The aim of the project is to examine how can we create superintelligent human-computer groups.
Publications:
-
E. B. Boumhaout, “A CAD Tool for Supermind Design,” Masters of Engineering (M.Eng.) Thesis, EECS, MIT, 2020.

The aim of the project is to examine how can we create superintelligent human-computer groups.
Publications:
E. B. Boumhaout, “A CAD Tool for Supermind Design,” Masters of Engineering (M.Eng.) Thesis, EECS, MIT, 2020.

This project will develop a parallel autonomy system to create a collision-proof car. We will instrument a Toyota vehicle with a suite of sensors pointed at the environment and at the driver to create situational awareness, both inside and outside the vehicle. We will develop and integrate the perception and decision- making software components to implement the parallel autonomy software core. We will also develop and implement novel algorithms that take control of the vehicle in dangerous situations to prevent accidents.
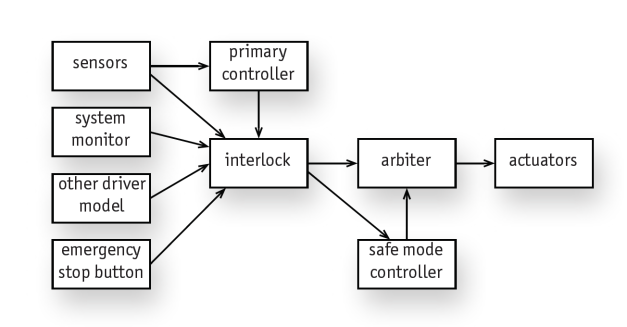
An architecture is proposed to mitigate the risks of autonomous driving. To compensate for the risk of failure in complex components that involve planning and learning (and other functions whose reliability cannot be assured), a small number of trusted components are inserted as an interlock to oversee the behavior of the rest of the system. When incipient failure is detected, the interlock switches the system to a safe mode in which control reverts to a conservative regime to prevent an accident.

Ground mobility is one of the key challenges in future mobile robots. Mobile robots can provide physical services that will be scarce in rapidly aging society. However, the mobility of current robots is limited to flat ground and cannot match with human’s mobility even in structured man-made environments. As elucidated by the failed mobile robots in the disaster of Fukushima Daiichi power plant, the lack of versatile, all-terrain mobility is a critical bottleneck for robots performing in compromised area.

Everyday tasks like driving a car, preparing a meal, or watching a lecture, depend on the brain’s ability to compute mappings from raw sensory inputs to representations of the world. Despite the high dimensionality of the sensor data, humans can easily compute structured representations such as objects moving in three dimensional space and agents with multi-scale plans and goals. How are these mappings computed? How are they computed so well and so quickly, in real time? And how can we capture these abilities in machines?
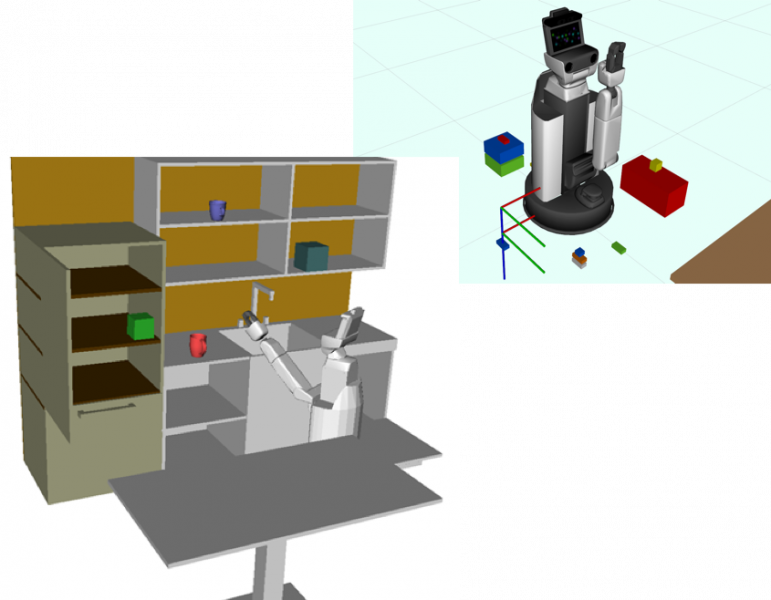
The last few years has seen the prolific development of robotic systems resulting in a variety of well-performing component technologies: image recognition, grasp detection, motion planning, and more. Despite this, few modern robotic systems have been successfully deployed to work alongside humans, making the TRI HSR University Challenge (i.e., cleaning up a play area) an invaluable benchmark. Component technologies alone are not sufficient – successful robotic platforms need to engage with humans and the environment at a high level.
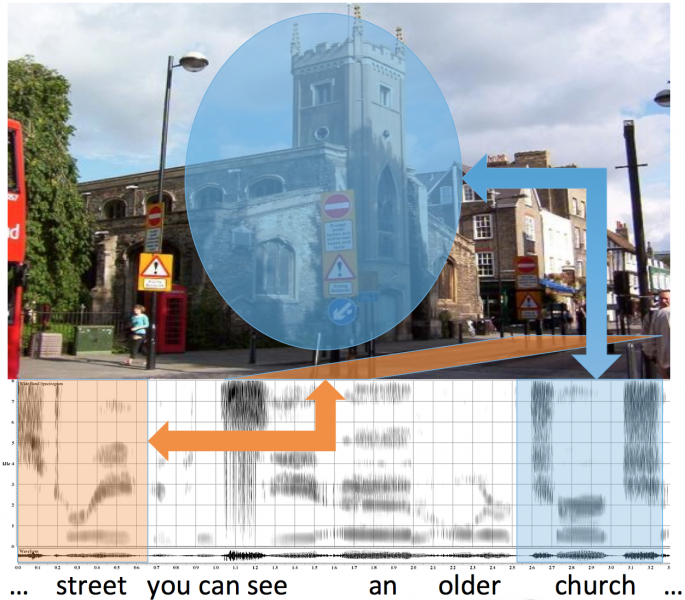
Language is our primary means of communication, and speech is one of its most convenient and efficient means of conveyance. Due to our ability to communicate by voice in hands-busy, eyes-busy environments, spoken interaction in the vehicle environment will become increasingly prevalent as cars become more intelligent, and are continuously perceiving (e.g., `listening' and `seeing') their environment.

Motion planning is critical for future driver assistance systems and autonomous cars. Algorithms that are able to design high-performance and provably safe motion through cluttered, dynamics environments are required for cars to operate in complex urban environments. In this research effort, we will develop theories to understand motion through cluttered, dynamic environments; we will also develop algorithms that realize natural, safe motion through cluttered environments, with provable completeness and optimality guarantees. We envision these algorithms to:
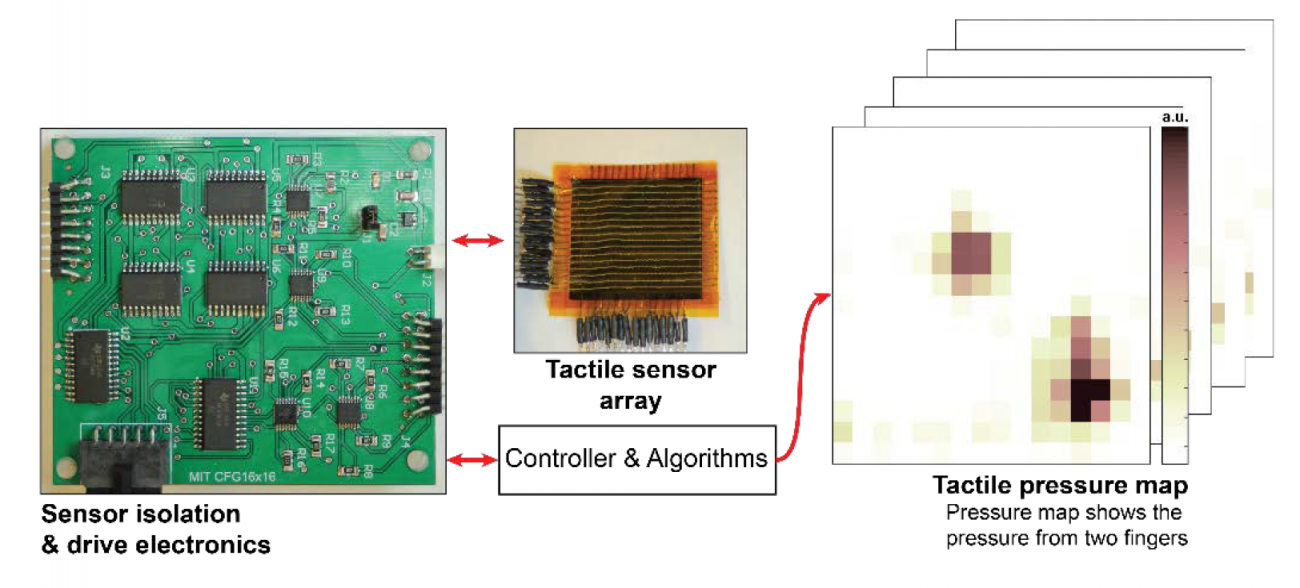
Humans grasp diverse objects while applying the right amount of force. However, modern robots function without the dense tactile feedback that living organisms are used to. In that sense, modern robots are tactile blind. The main goal of this proposal is to investigate a series of fabrication techniques and associated electronics and algorithms to enable dense tactile sensing for a variety of applications, but specifically in robotics manipulation and control.
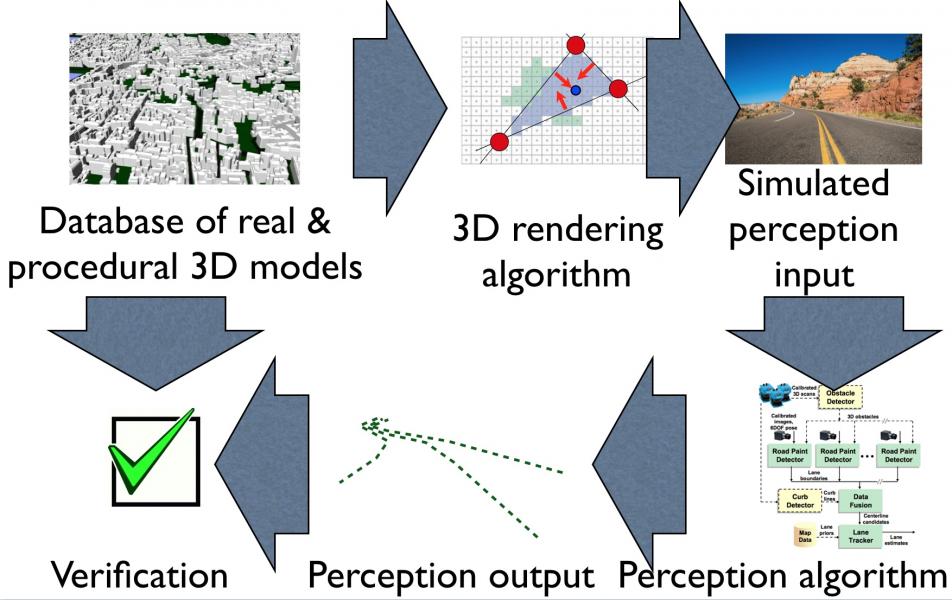
We aim to rigorously characterize the sensitivity of vision-in-the-loop driving controllers in increasingly complex visual tasks. While rooftop lidar provides a spectacular amount of high-rate geometric data about environment, there are a number of tasks in an autonomous driving system where camera-based vision will inevitably play a dominant role: dealing with lane markings and road signs, dealing with water/snow and other inclement weather conditions that can confuse a lidar, and even dealing with construction (orange cones), police officers, and pedestrians/animals.

When is driving most risky? When do drivers find driving difficult or stressful? Why are these situations more risky or difficult for the driver? Should the car momentarily take over whenever the driver is distracted? Drivers are often distracted: they adjust the radio, talk to passengers, think about their day, and look at the scenery. If a semi-autonomous car were to take over whenever the driver were distracted, this might effectively require a fully autonomous vehicle!

Traffic flow instabilities (such as stop-and-go traffic and "phantom traffic jams") can be suppressed using "bilateral control". We are studying how best to implement bilateral control and make it acceptable to drivers. We need to determine what fraction of vehicles need to implement bilateral control before significant benefit can be observed. This is so that we can understand the transition to a world where every vehicle implements bilateral control.

We are developing soft skin for robots with sensitivity exceeding that of human skin. It gives information about shape, texture, normal force and shear force. The soft sensitive fingers will give robots advantages in many aspects of manipulation, whether on the factory floor or in the home. The fingers can tell the robot about the 3D pose of a grasped object, and whether the object is hard, soft, smooth, or rough. In this project we are building improved touch sensing hardware, and are developing algorithms to exploit the rich information being provided.
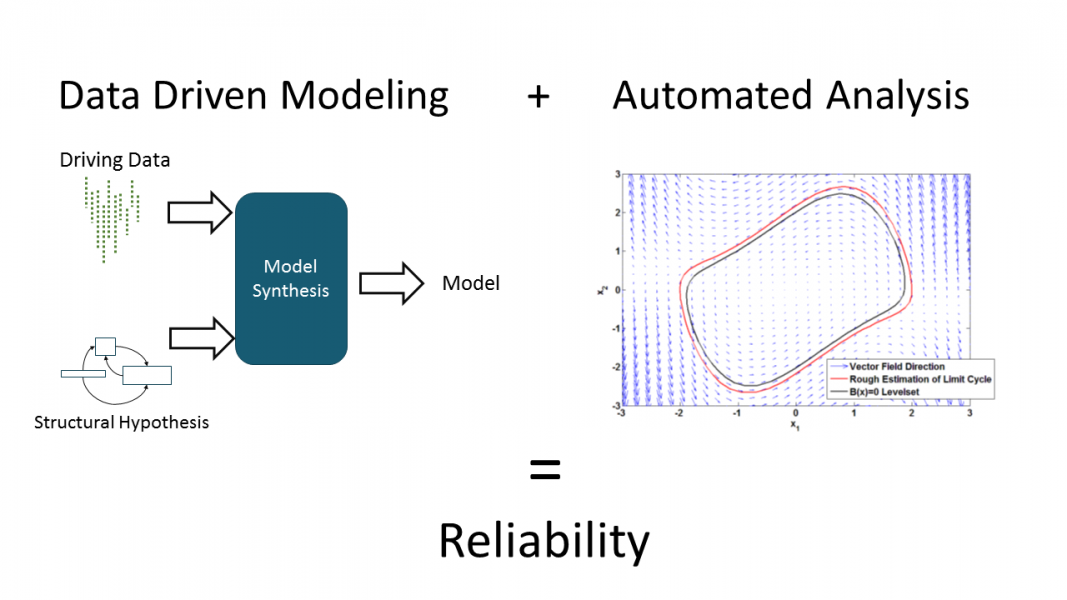
Autonomous cars face two major challenges. First, the system needs to analyze large amounts of data from its dynamic environment, and react intelligently and quickly. Second, any such reaction needs to be safe; even a small probability of accident per mile can be catastrophic in a mass deployment. To achieve these two goals, our project aims to develop a unified framework that brings together the advances in machine learning and control that can make autonomous driving possible with the advances in verification that can make it safe.

Despite improvements in automobile technology and comfort, modern driving is an unnecessarily stressful and dangerous activity. The primary reason for this is cognitive overload on the driver at multiple levels. The Toyota-CSAIL partnership puts forward the exciting vision of safer and less stressful driving through a “parallel” autonomous system that assists the driver by watching for risky situations, and by helping the driver take proactive, compensating actions before they become crises.
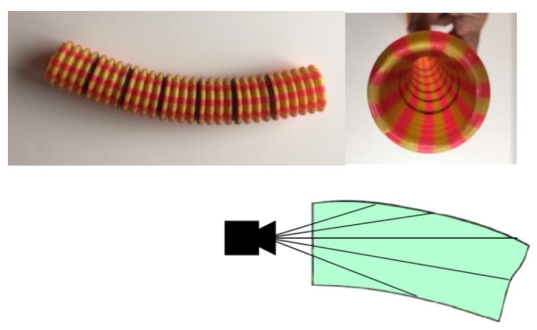
We will develop a soft robot hand with proprioception to be used in the HSR university challenge. It’s important for a robot to know the configuration of its own parts, i.e., to have proprioception. For example, in grasping an object, the robot positions the hand, and fingers carefully. In soft robotics the rules are relaxed: a soft hand can run open loop, mechanically adjusting for errors. But without proprioception the robot doesn’t know what it is doing.
[June-1-2018 to current]
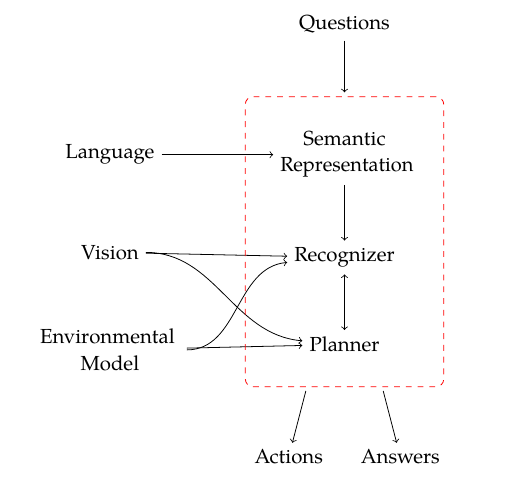
Safe and controllable autonomous robots must understand and reason about the behavior of the people in the environment and be able to interact with them. For example, an autonomous car must understand the intent of other drivers and the subtle cues that signal their mental state. While much attention has been paid to basic enabling technologies like navigation, sensing, and motion planning, the social interaction between robots and humans has been largely overlooked. As robots grow more capable, this problem grows in magnitude since they become harder to manually control and understand.
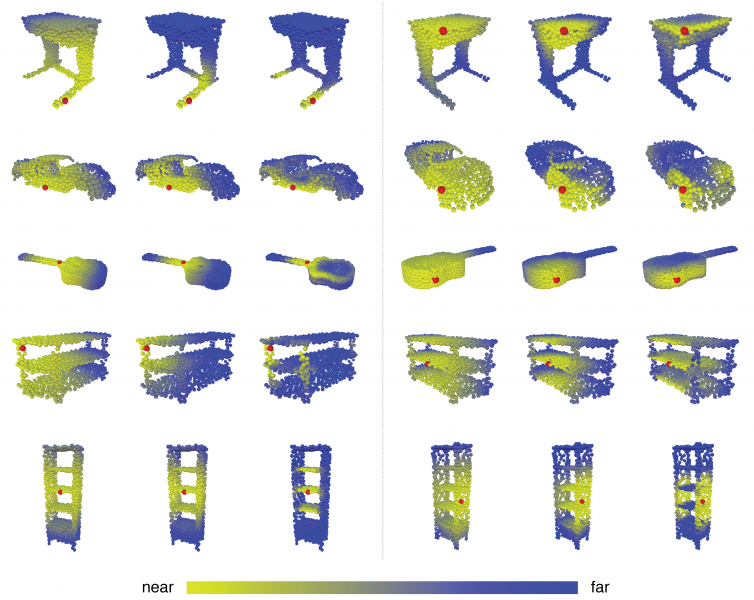
Machine learning from 3D shapes is fundamentally different from learning on images. Rather than shoehorning popular image-based deep networks to take in shape data, we will build deep learning for point clouds, CAD models, and triangulated surfaces from the ground up. In particular, we will design, implement, train, and test networks built from operations that are mathematically well-posed and practically-minded specifically for geometric data.

When humans and autonomous systems share control of a vehicle, there will be some explaining to do. When the autonomous system takes over suddenly, the driver will ask why. When an accident happens in a car that is co-driven by a person and a machine, police officials, insurance companies, and the people who are harmed will want to know who or what is accountable for the accident. Control systems in the vehicle should be able to give an accurate unambiguous accounting of the events.

The goal of this project is to develop the technologies for a robot manipulator to perform autonomous object exploration of previously unseen objects and to iteratively adapt/refine/verify its own perception and manipulation skills. In particular, we want to demonstrate that the following are possible and practical:
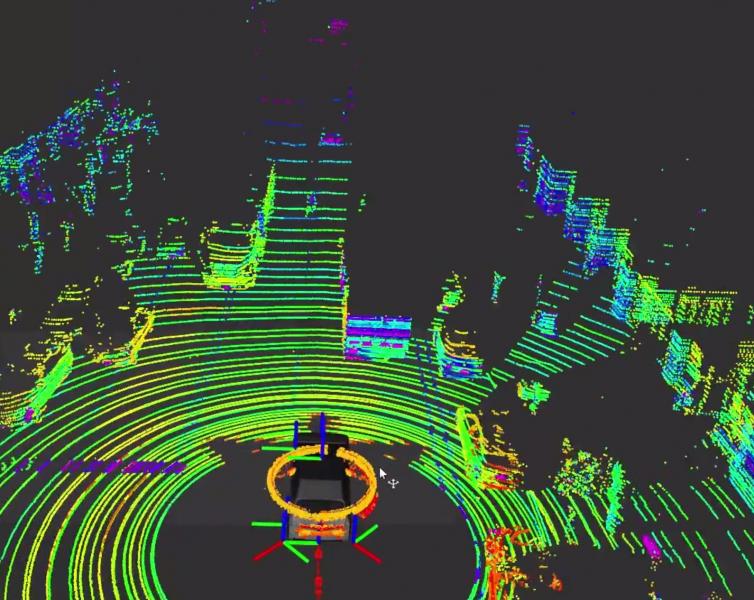
While predictions abound that fully autonomous self-driving cars will become widely available in just a few years, in reality there are major research challenges to address for creating fully autonomous self-driving cars.
Casualties are in no small part rooted in stress. In California, for example, drivers can avoid a first ticket by attending driving school. One might expect California driving schools to focus on reinforcing the rules of the road. Instead, they focus on teaching drivers about techniques for stress and time management, as a way to address overly aggressive, reckless driving behavior.

Distracted driving is one of the leading causes of car accidents - in the United States, more than 9 people are killed and more than 1,153 people are injured each day in crashes that are reported to involve a distracted driver. The distractions can be visual (i.e., taking your eyes off the road), manual (i.e., taking your hands off the wheel) or cognitive (i.e., taking your mind off the road because of cell-phone use/alcohol/drugs, etc) in nature. Within these, cell-phone use and driving under the influence are two of the leading causes of accident fatalities.
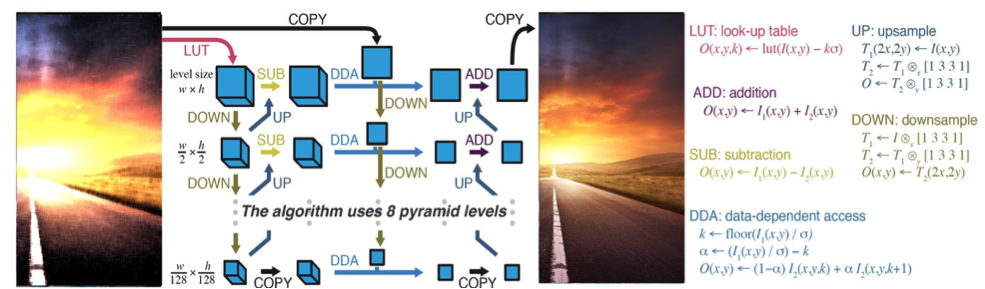
Perception is a critical component of autonomous and assisted driving. Enormous amounts of data from cameras and other optical sensors (e.g. Lidar) need to be processed in real time and with as low a latency as possible to allow cars not only to locate themselves, but also to react in a fraction of a second to unexpected situations. Reaching this level of performance has traditionally been a struggle with large implementation costs.
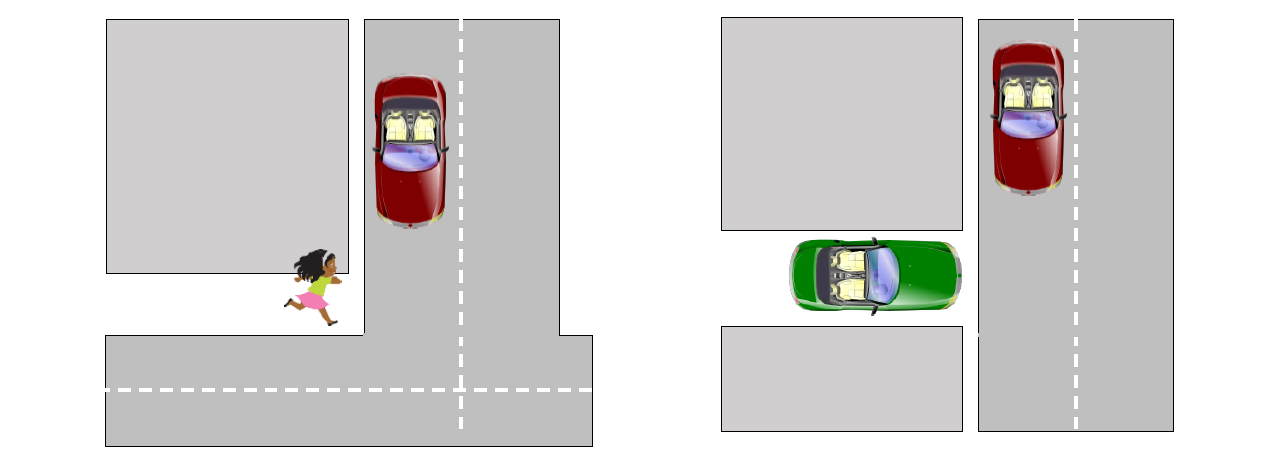
Automatic detection of people, cars, and obstacles is critical for future driver assistance systems and robot navigation. This is particularly important when the object is not in the field-of-view of the car and its driver. Many accidents happen today due to inability to detect a child running around the corner or a car pulling out of an occluded driveway, as shown in the figure below. The future of driver assistance systems and autonomous cars critically depends on how well they can deal with blind spots and hidden objects.